Last year, I was testing a AI agent I'd built - a 19 node LangGraph pipeline that serves about 20,000 users. I pushed a change to the retry logic, went to grab lunch, and came back to find it had been calling GPT - 4 in an infinite loop for three hours. $200 gone. No alerts, no spending caps, nothing to stop it.
I fixed the bug in 10 minutes. Setting up the spending caps and monitoring that should have been there from the start took the rest of the afternoon.
That afternoon taught me something that 6 months of AI/ML courses never did: the hard part of AI engineering isn't the AI. It's everything around it.
How I got here (the long way)
I started working with LLMs in 2023. Like a lot of developers, I bought Udemy courses, bookmarked too many YouTube playlists, and told myself I was going to become an AI engineer. Then I spent six months watching lectures instead of building anything.
One course had 22 hours of content on neural network architecture. I watched the whole thing. Took notes. Felt smart. Then someone asked me to build a chatbot that could answer questions about a PDF, and I had no idea where to start.
I remember sitting at my desk at 11pm, halfway through a different course on training GPT from scratch, staring at a matrix multiplication I couldn't follow, wondering whether AI engineering was for me. I'd been "learning" for months and couldn't build a chatbot. I could sort of explain self - attention on a whiteboard, but I couldn't build anything someone would pay for.
The problem is that most AI courses are designed by researchers. They start with the math, move to the theory, and maybe you build a toy project in the last module. But in the real world, very few developers train models from scratch. I've never written a PyTorch training loop for my production pipeline. What I actually do - and what most AI engineers do - is call APIs, build retrieval systems, wire up tool calling, handle failures, and make sure the thing keeps running when traffic spikes or a model provider has an outage.
I was studying for a career that didn't look anything like the actual job. It wasn't the field that was wrong. It was the learning path.
The project that actually taught me something
The turning point was a Thursday night when I decided to stop studying and just build.
I had a pile of company docs, maybe 50 PDFs, that our team constantly searched through for answers. I thought: what if I could just ask questions and get answers with page numbers?
I used pymupdf to extract text, chunked it, stored it in ChromaDB, and wired up the OpenAI API to answer questions using the retrieved chunks.
The first version was terrible. Confident hallucinations. Irrelevant retrievals. Chunking that split sentences in half and destroyed context.
But I learned more from debugging that broken system in one weekend than from three months of transformer lectures. I had real problems for the first time. Why is this chunk being retrieved when it's clearly wrong? Why does the model fabricate an answer when the context doesn't support one? How do I even measure whether this is getting better?
Each fix taught me something I still use. Overlap on chunks improved retrieval. Telling the model to say "I don't know" cut hallucinations. Adding a reranker made the answers noticeably better. Within two weeks, my team was using it daily - an ugly Streamlit app with zero styling that saved people 20 minutes every time they had a question.
What production taught me that tutorials never could
That first RAG project was a toy compared to what came after. Building and maintaining LLM systems with real users depending on them is a different game entirely, and the lesson that took me longest to internalize was about agents.
I see developers reaching for autonomous agents when a simple chain of 3 LLM calls would be faster, cheaper, and easier to debug. I've built multi - agent systems. I've also ripped them out and replaced them with deterministic pipelines when the complexity wasn't justified. The AI engineering Twitter bubble makes it sound like everything should be an agent. In production, the most valuable judgment call is often deciding it shouldn't be.
Why I built this roadmap (and why it's different)
There are a lot of "become an AI engineer in X weeks" guides out there. I've read most of them. They tend to fall into two categories: academic syllabi repackaged as career guides, or surface - level tutorials that stop at "call the OpenAI API."
This one is different because it's ordered by what I actually needed to know, in the order I needed to know it, based on building production systems - not based on how a CS curriculum would structure it. Fine - tuning comes in week 23, not week 3. Evaluation shows up early and often, not as an afterthought. The "boring" production stuff (monitoring, caching, cost controls) gets four full weeks because in my experience, that's where most teams get stuck.
Every week has one topic, one library, and one project you can finish in 5 days. Working code, not slides. Push to GitHub on Sunday. Move on.
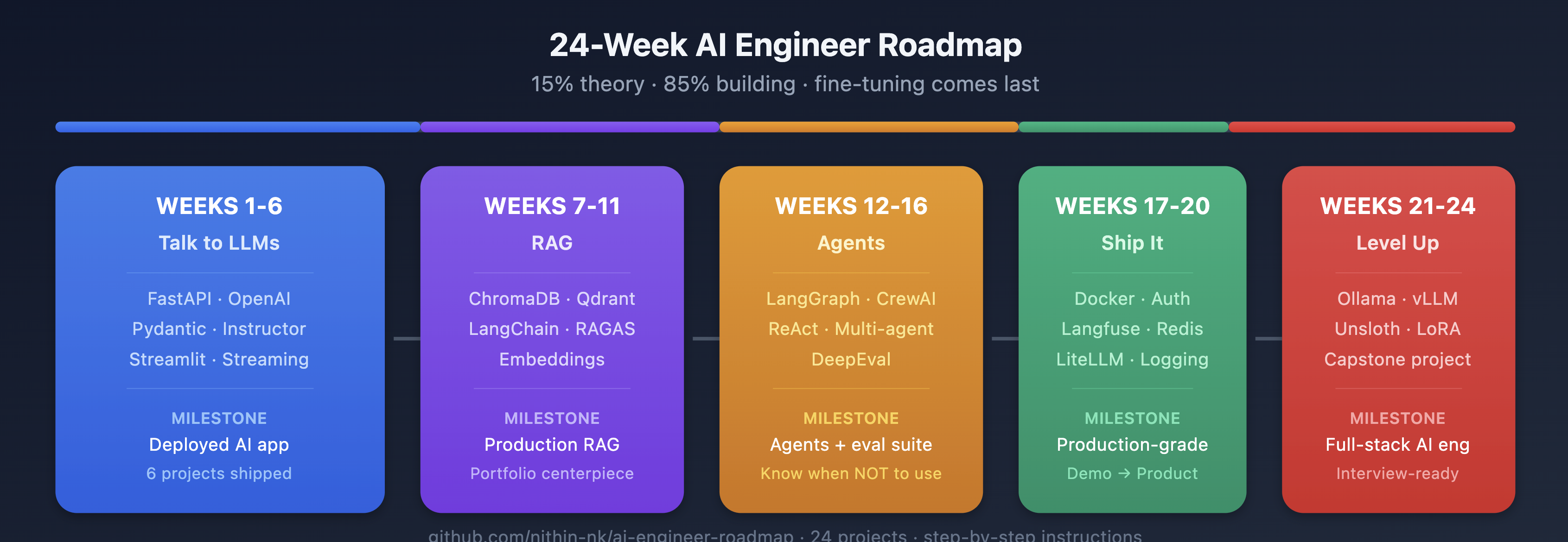
The 24 weeks
Weeks 1–6: Talk to LLMs
Stack: FastAPI · OpenAI/Anthropic APIs · Pydantic · Instructor · Streamlit
You start building from day one. FastAPI basics (week 1), then your first LLM API call and a chatbot (week 2), then prompt engineering where you compare 5 different prompts for the same task and measure which one actually performs best (week 3).
Week 4 changed how I build everything: structured outputs. Instead of the LLM returning free - text you have to parse, you get clean JSON that maps to a Pydantic model. Before I discovered Instructor, I was doing regex on LLM outputs. That's a dark period I don't like to talk about.
Week 5 is tool calling - the LLM decides which of your Python functions to invoke. This is the mechanism behind ChatGPT plugins. Once you understand it, agent frameworks stop feeling like magic and start looking like what they are: a while loop with some routing logic.
By week 6, you put it together in a Streamlit app with streaming, deploy it, and you've shipped your first AI product.
Weeks 7–11: RAG
Stack: sentence - transformers · ChromaDB · Qdrant · LangChain · RAGAS · Docker
If you learn one thing from this roadmap, make it RAG. Over half of the enterprise AI systems I've worked with use some form of retrieval - augmented generation. This is what gets you hired.
You start with embeddings (week 7), then build "chat with your PDF" (week 8) - the project I described above. It will give bad answers at first. I've included the exact failures I hit and how to fix each one, because I've seen every developer hit the same walls.
Weeks 9–10, you add reranking and evaluation with RAGAS. Most people skip evaluation. Don't. I spent months shipping prompt changes based on gut feel - "this feels like it's working better" - before I set up proper eval frameworks covering SQL validity, execution accuracy, semantic equivalence, and robustness testing. My iteration speed tripled. Not because the evals were fancy, but because I stopped wasting cycles on changes that looked good on three examples and broke everything else. Once you have metrics, you stop guessing and start engineering.
Week 11, you make it production - ready. FastAPI, Qdrant, Docker. docker compose up starts the whole thing. This is your portfolio centerpiece.
Weeks 12–16: Agents
Stack: LangGraph · CrewAI · DeepEval
Week 12 is my favorite. You build an agent from scratch. No frameworks. Just the API and a while loop. Everyone should do this once. After you do, you can read LangGraph's source code and actually follow what's happening - which matters when something breaks and you need to figure out why fast.
Weeks 13–15, you move to LangGraph and multi - agent systems with CrewAI. But here's the thing I keep coming back to: most of you won't need agents at work. Not yet. I've built agent systems. I've also replaced them with simpler pipelines when the complexity wasn't justified. The most valuable skill in this section is the judgment to know which approach fits the problem.
Week 16 is evaluation. Automated test suites for everything you've built.
Weeks 17–20: Ship it
Stack: Docker Compose · Langfuse · Redis · LiteLLM · structlog
This is the section that separates demos from products. Auth, rate limiting, prompt injection defense, monitoring with Langfuse, Redis caching, cost tracking.
I can tell you from experience: the production systems I maintain spend more engineering time on caching, observability, and error handling than on the LLM calls themselves. That retry loop bug I opened with? It happened because I didn't have proper monitoring yet. Week 18 would have prevented it. The semantic caching that cut my response times from 70 - 90 seconds down to 30 - using Redis and vector similarity to catch repeated queries? That's week 19. The LLM call is often the easy part. Everything around it is where the engineering actually lives.
This section isn't exciting. But if you skip it, you'll learn these lessons the way I did - in production, at the worst possible time.
Weeks 21–24: Level up
Stack: Ollama · vLLM · Unsloth (LoRA/QLoRA)
NOW you learn fine - tuning and open - source models. Not month 1. Week 21.
By this point you've built 20+ projects and you actually know when fine - tuning solves a problem that prompting and RAG can't. In my experience, that's less often than Twitter suggests. Most of the fine - tuning hype comes from people selling fine - tuning courses.
Week 24 is your capstone. One end - to - end project: Docker Compose, eval results, monitoring dashboard, architecture diagram. This is what you walk into interviews with.
Some opinions
The best AI engineers I've worked with were the best software engineers first. Not the ones who knew the most about transformers. The ones who could design a cache layer, set up proper monitoring, and debug a race condition at 2am. If you can build a REST API, manage state, handle errors, and deploy a Docker container, you're 70% of the way to being an AI engineer. The remaining 30% is the easier part to learn.
You should be suspicious of anyone who tells you to fine - tune first. In my experience, prompting and RAG solve the problem about 90% of the time. Fine - tuning is expensive, hard to evaluate, and locks you to a specific model. I've seen teams spend weeks fine - tuning when a better system prompt would have done the job. The roadmap puts fine - tuning in week 23 on purpose - not because it's unimportant, but because you need to exhaust the simpler options first to know when it's actually the right call.
LangChain and LangGraph are not the enemy. I see a lot of "ditch the frameworks" takes online. I've built agents both ways - raw API with a while loop, and with LangGraph. The framework version is easier to maintain at scale. But you should build it raw first (week 12) so you understand what the framework is doing. Otherwise you're debugging abstractions you don't understand, which is worse than having no framework at all.
Start now
Step 1: Open this repo: https://github.com/nithin-nk/ai-engineer-roadmap
Step 2: Read week-01/idea.md. It's a FastAPI expense tracker. Every step is written out. The code is there.
Step 3: Open your editor and build it.
ai-engineer-roadmap/
├── README.md
├── week-01/idea.md ← Start here
├── week-02/idea.md
├── ...
└── week-24/idea.mdBy week 6 you'll have a deployed AI app. By week 11, a production RAG system. By week 16, agents with automated evaluation.
I'm still figuring a lot of this out. The field moves fast enough that everyone is. But I've spent enough time in production to know that the developers who build things - even broken, ugly things - learn faster than the ones who watch lectures about building things. Every project I've shipped started out embarrassing. The Streamlit app with no CSS. The agent that looped forever. The cache that returned stale answers for a week before anyone noticed.
Each one taught me something I couldn't have learned any other way. Yours will too.
Go build something.
Comments (0)